-
新西兰电信公司Spark斥资2.21亿美元用于数据中心和5G新计划
Spark主席史密斯在当地时间5日的简报会上公布了新战略,他表示 Spark 在过去三年中通过新技术和简化实现了增长,现在能够为未来的扩张进行投资。 【详细】
-

-
在互联网运营商等大规模、超大规模用户中,Spark是最受欢迎的大数据系统,Spark对于内存依赖性很强,所以当负载提高时,硬件平台的内存挑战就会十分明显【详细】
-

-
Hive和Spark凭借其在处理大规模数据方面的优势大获成功,换句话说,它们是做大数据分析的。本文重点阐述这两种产品的发展史和各种特性,通过对其能力的比较,来说明这两个产品能够解决的各类复杂数据处理...【详细】
-
-
我们被各方的数据所包围。随着数据每两年增加一倍,数字世界正在快速追逐物理世界。据估计,到2020年,数字宇宙将达到44个zettabytes - 与宇宙中的恒星一样多的数字位。【详细】
-

-
总的来说,Spark采用更先进的架构,使得灵活性、易用性、性能等方面都比Hadoop更有优势,有取代Hadoop的趋势,但其稳定性有待进一步提高。我总结,具体表现在如下几个方面。 【详细】
-


-
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。它产生于 UC Berkeley AMP Lab,继承了 MapReduce 的优点,但是不同于 MapReduce 的是,Spark 可以将结果保存在内存中,一直迭代计算下去...【详细】
Spark 2019-04-19
-

-
彻底掌握Spark框架源码的每一个细节;根据不同的业务场景的需要提供Spark在不同场景的下的解决方案;根据实际需要,在Spark框架基础上进行二次开发,打造自己的Spark框架; 【详细】
-

-
Spark提供了一个简单的方式在集群之间并行化这些应用,隐藏了分布式系统、网络通信和容错处理的复杂性。【详细】
-

-
据外媒报道,新西兰移动运营商Spark计划从2020年开始提供5G移动服务,该运营商希望能够及时为美洲杯提供5G无线通信技术,但其计划能否实现将取决于政府的政策决定以及必要频谱的可用性。 【详细】
-

-
自从数据处理需求超过了传统数据库能有效处理的数据量之后,Hadoop 等各种基于 MapReduce 的海量数据处理系统应运而生。从 2004 年 Google 发表 MapReduce 论文开始,经过近 10 年的发展,基于 Hadoop 开...【详细】
-

-
为了增加混淆,Spark和Hadoop经常与位于HDFS,Hadoop文件系统中的Spark处理数据一起工作。但是,它们都是独立个体,每一个体都有自己的优点和缺点以及特定的商业案例。本文将从以下几个角度对Spark和Hadoo...【详细】
-

-
Spark的误解-不仅Spark是内存计算,Hadoop也是内存计算
市面上有一些初学者的误解,他们拿Spark和Hadoop比较时就会说,Spark是内存计算,内存计算是Spark的特性。【详细】
-

-
Hadoop在大数据领域享有多年垄断权,随着该领域开始出现新生力量,其统治地位正在逐渐下滑。年初的调查中,Hadoop被列为2018年大数据领域的“渐冻”趋势之一,Gartner的调查也揭示了Hadoop使用量的下滑,...【详细】
-

-
由雅虎为工程师和数据科学家打造的Apache Hadoop曾因巨大的潜力而备受称赞,但如今它却受到了更快的产品的影响,而这些产品往往来自于它本身的生态系统——Spark就是其中之一。【详细】
-

-
Spark采用一个统一的技术堆栈解决了云计算大数据的如流处理、图技术、机器学习、NoSQL查询等方面的所有核心问题,具有完善的生态系统,这直接奠定了其一统云计算大数据领域的霸主地位。【详细】
-

-
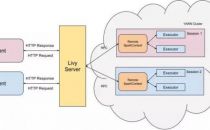
Livy是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:1.提交Scala、Python或是R代码片段到远端的Spark集群上...【详细】
-
-
和 Hadoop 一样,Spark 提供了一个 Map/Reduce API(分布式计算)和分布式存储。二者主要的不同点是,Spark 在集群的内存中保存数据,而 Hadoop 在集群的磁盘中存储数据。【详细】
-

-
将定制的Spark和Hadoop试点项目转移到生产中是一项艰巨的任务,但容器技术缓解了这种艰难的过渡。【详细】
-

-
作为一个开源的数据处理框架,Spark 是如何做到如此迅速地处理数据的呢?秘密就在于它是运行在集群的内存上的,而且不受限于 MapReduce 的二阶段范式。这大大加快了重复访问同一数据的速度。听上去好像 Spa...【详细】
-

-
很多初学者其实对Spark的编程模式还是RDD这个概念理解不到位,就会产生一些误解。 比如,很多时候我们常常以为一个文件是会被完整读入到内存,然后做各种变换,这很可能是受两个概念的误导:【详细】
Spark 2016-04-22
-

-
数据科学是一个广阔的领域。我自认是一个数据科学家,但和另外一批数据科学家又有很多的不同。数据科学家通常分为统计科学家和数据工程师两个阵营,而我正处于第二阵营。【详细】
-

-
大数据,官方定义是指那些数据量特别大、数据类别特别复杂的数据集,这种数据集无法用传统的数据库进行存储,管理和处理。大数据的主要特点为数据量大(Volume),数据类别复杂(Variety),数据处理速度快(Ve...【详细】
-
-
有一句古老的格言是这样说的,如果你向某人提供你的全部支持和金融支持去做一些不同的和创新的事情,他们最终却会做别人正在做的事情。如比较火爆的Hadoop、Spark和Storm,每个人都认为他们正在做一些与这...【详细】
-

-
说人话:其实就是讲Spark Streaming 的好处与坑。好处主要从一些大的方面讲,坑则是从实际场景中遇到的一些小细节描述。【详细】
-

-
谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生。但我们往往对它们的理解只是提留在字面上,并没有对它们进行深入的思考,下面不妨跟我一块看下它们究竟有什么异同。 解决问题【详细】
-

-
Apache的Spark,一个新的大数据框架, 已被描述为一个替代Hadoop的可能。一些观点认为,Spark由于比旧的框架更容易理解和强大,因此在新兴的大数据和分析项目中更适合。【详细】
-
-
2016年大数据领域会发生什么情况?考虑到如今在深层神经网络和规范性分析方面取得的进展,你可能觉得这个问题很好回答。而实际上,来自业界的大数据预测大不相同,本文精选出了最值得关注的33个预测,为您...【详细】
-
-
谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生。都是与处理数据有关,但是它们又有什么不同呢?【详细】
-

-
本文有两重目的,一是在性能方面快速对比下R语言和Spark,二是想向大家介绍下Spark的机器学习库。【详细】
-

-
通常人们认为Spark的性能和速度全面优于MapReduce,但最新的对决显示MapReduce在某些方面也有胜场,而且数据规模越大优势越大。【详细】
-
-
在极短的时间内,Apache Spark 迅速成长为大数据分析的技术核心。这使得业内人士担心在这个技术更新如此之快的年代,它是否会同样快被淘汰呢?【详细】
-

-
对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益大化,例如电商网站,网站推荐系统期望能实时根据顾客的点击行为分...【详细】
-
-
Hadoop与分布式数据处理 Spark VS Hadoop有哪些异同点?
虽然Spark与Hadoop有相似之处,但它提供了具有有用差异的一个新的集群计算框架。首先,Spark是为集群计算中的特定类型的工作负载而设计,即那些在并行操作之间重用工作数据集(比如机器学习算法)的工作负...【详细】
-

-
Spark是发源于美国加州大学伯克利分校AMPLab的集群计算平台,它立足于内存计算,性能超过hadoop百倍,从多迭代批量处理出发,兼收并蓄数据仓库、流处理和图计算等多种计算范式,是罕见的全能选手。Spark采...【详细】
-
-
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供...【详细】
-
-
继今年六月份IBM宣布对Spark提供三百万美金的投资,IBM现在推出Apache Spark 云服务,立志打造一个完全数据分析平台。【详细】
-

-
新兴的Spark技术有望取代大数据框架中广泛应用的MapReduce技术。【详细】
-

-
新可视化帮助更好地了解Spark Streaming应用程序
日前,在Spark1.4.0中新推出了可视化功能,用以更好的了解Spark应用程序的行为。Spark贡献者Tathagata Das、Shixiong Zhu和Andrew Or又撰文重点介绍为理解Spark Streaming应用程序而引入的新可视化功能。【详细】
-
